

При оформлении офисного пространства выбор напольного покрытия играет ключевую роль, определяя не только эстетику

Скандинавский дизайн подчеркивает связь с природой, предпочитая натуральные материалы и светлые оттенки. Он сочетает

Покупка нового покрытия для пола всегда связана с выбором из множества вариантов. Однако, если
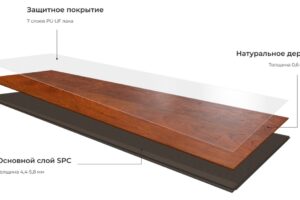
В современной отделке интерьера выбор напольного покрытия играет ключевую роль. От этого зависят как

Холодная сварка для металла позволяет получить прочное соединение с высокими характеристиками при проведении плановых
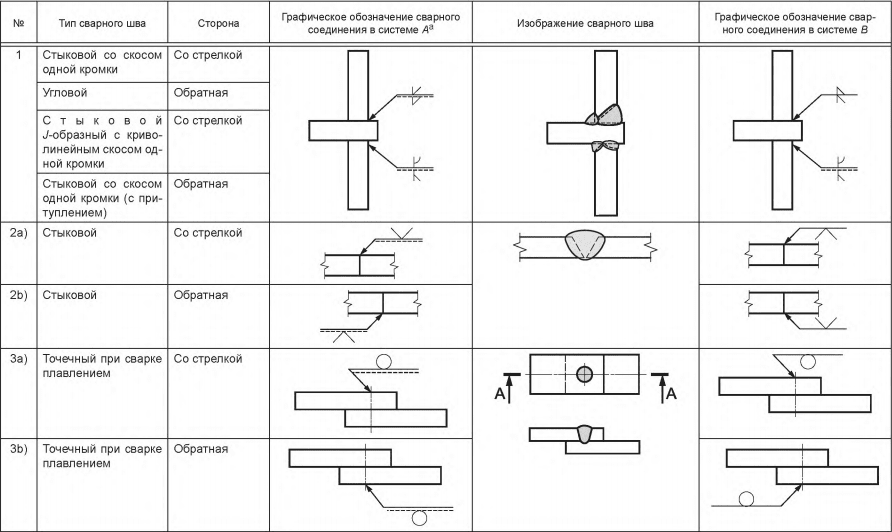
В чем состоит сущность сварки контактным методом. Одностороннее и двустороннее сваривание. Стыковой метод сплавления


Советы и рекомендации как подобрать оптимальный сварочный аппарат для бытового применения: какие они бывают,
![Сварка алюминия электродом дома [как выбрать, инструкция]](http://takorest.ru/wp-content/uploads/2/2/d/22da6bb91acafbe84f2455e0fd9624f2.jpeg)
Особенности сварки алюминия и его сплавов в домашних условиях. Технологический процесс и пошаговое описание
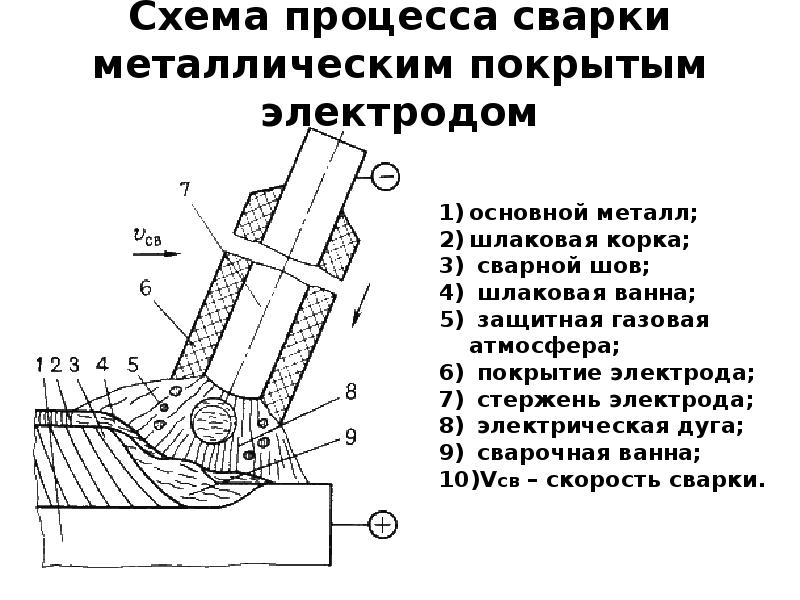
Ручная дуговая сварка покрытым электродом MMA: все о технологии, процессе и оборудовании. Особенности, преимущества

Сварочный карандаш - средство для быстрого соединения металлических конструкций. Для его применения не требуется

Автоматическая сварка — высшая степень механизации электродуговой сварки, во время нее происходит самостоятельное образование

Современный сварщик – ювелир, технарь и профессионал высокого класса, которому нужно быть в курсе

По эффективности сварка нержавейки полуавтоматом превосходит многие другие. Специфика материала, особенности способа, поэтапные действия

Ремонт колесных дисков - можно ли восстанавливать? Какие бывают повреждения? Какие диски можно ремонтировать?

Переменный входной ток, размеры провода и советы как собрать простой сварочный аппарат в домашних

Ремонт сварочных инверторов: где лучше в домашних условиях или в сервисном центре? Основные причины
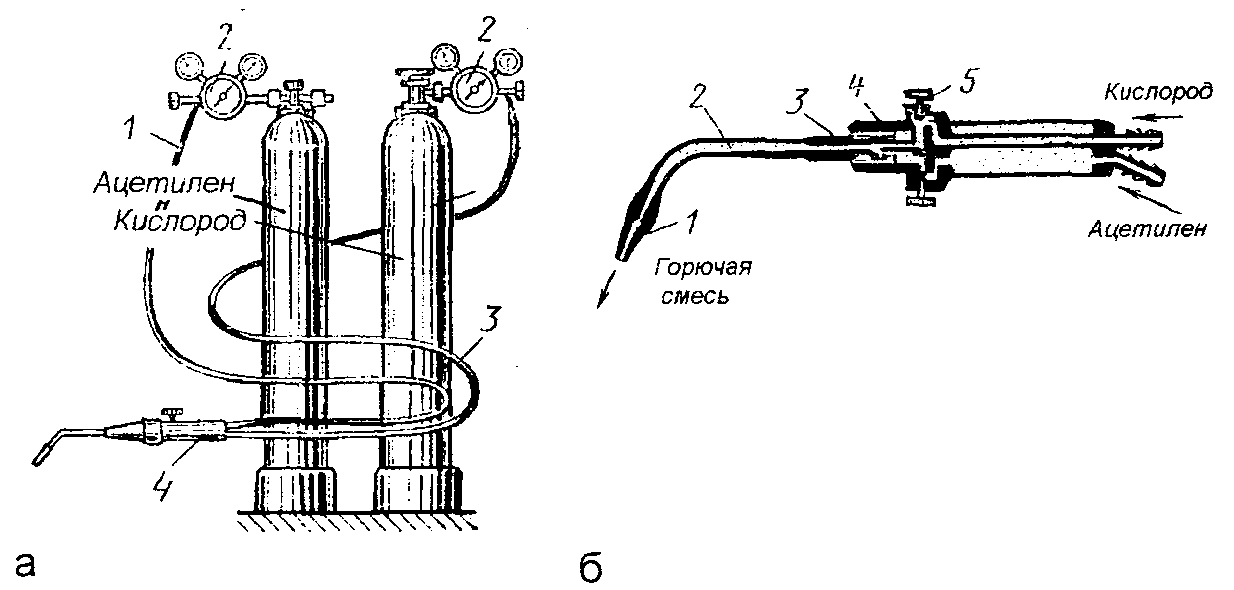
Газосварочный пост: понятие, стационарный и портативный виды, необходимое оборудование, преимущества и недостатки.
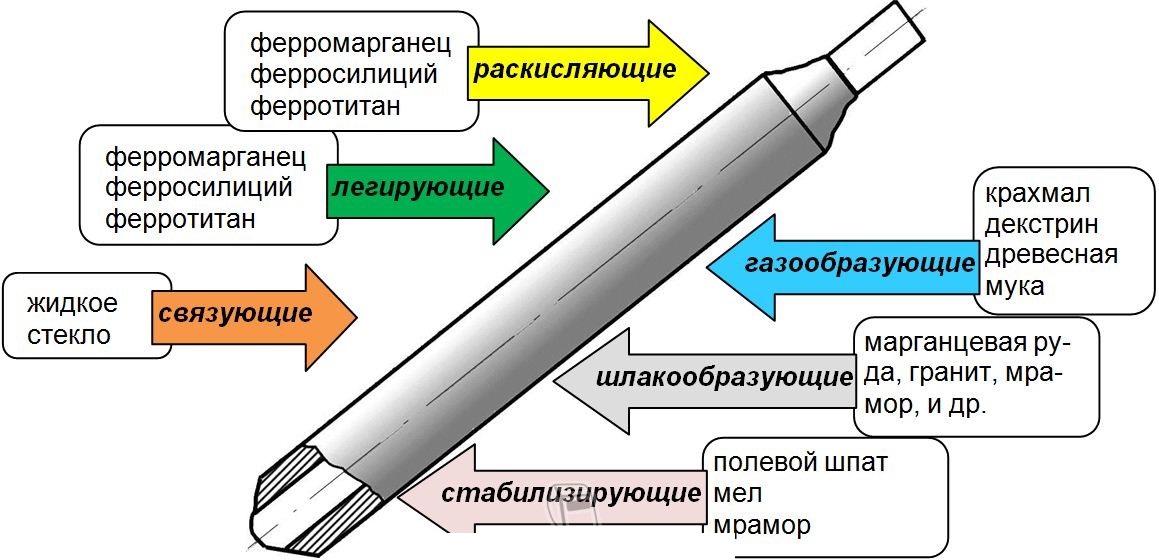
В этой статье в мы расскажем, какие бывают неплавящиеся стержни и где они применяются.

Сварка – один из самых популярных способов неразъемного соединения металлических деталей. При этом выделяют
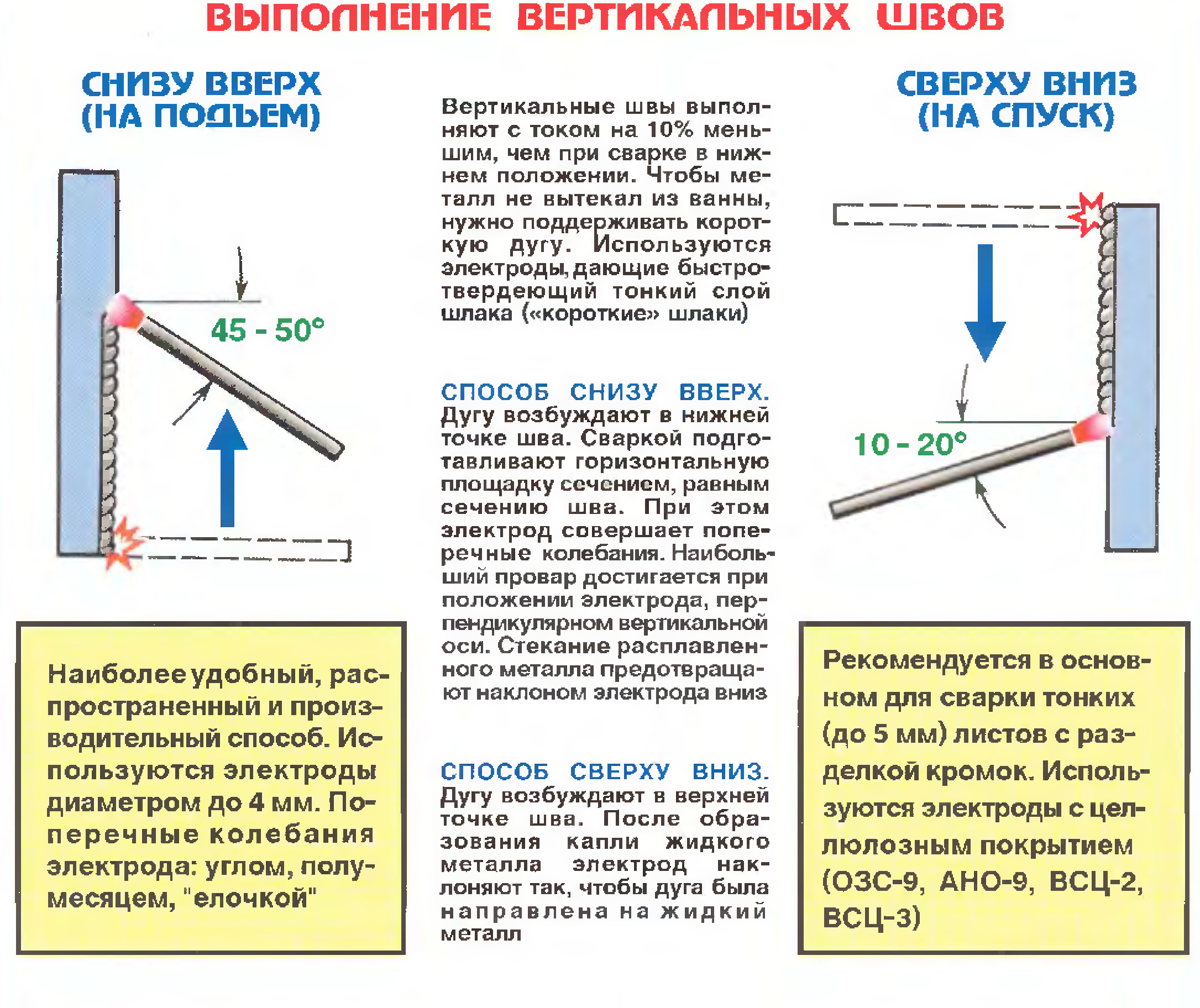
Как правильно варить вертикальный шов инвертором? Особенности сварки вертикальных швов металла 1,5 мм. Технология

Сваривание нержавейки - самая трудная задача, поскольку ванна сильно текучая, что заметно усложняет формирование

Обзор лучших сварочных краг на 2022 год. Ознакомление с особенностями и преимуществами перчаток.
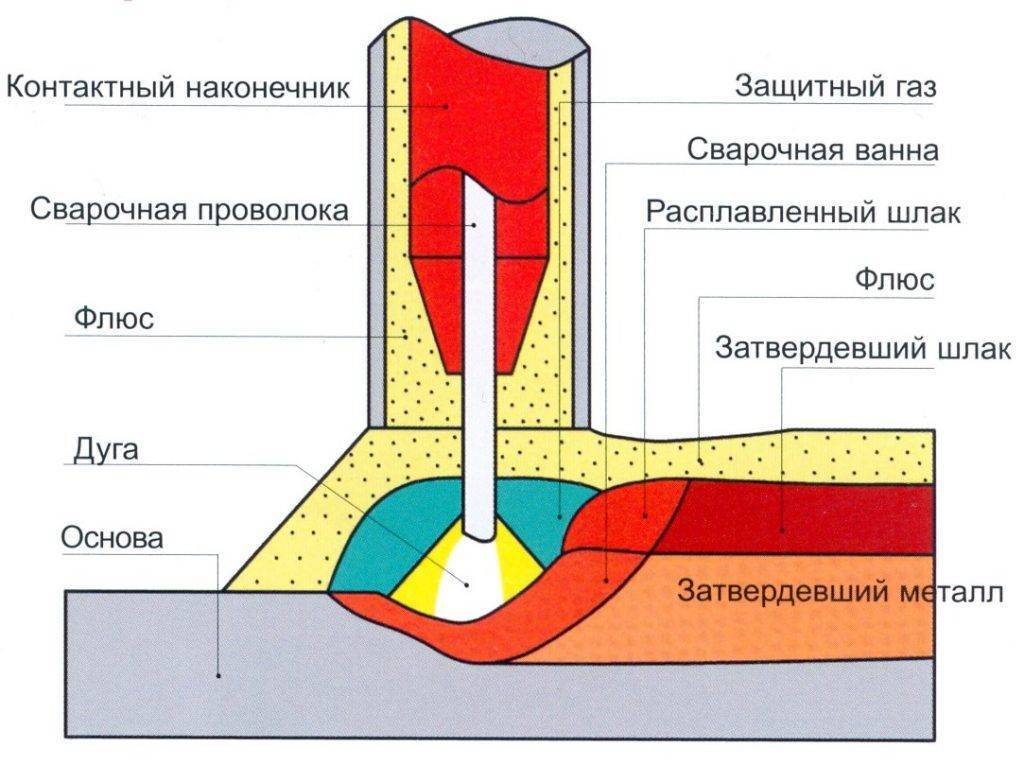
В этой статье вы узнаете, что такое сварочные легкоплавные флюсы для сварки. Какие бывают

Сварная оцинкованная сетка для забора является очень популярным материалом в изготовлении изгородей различного типа
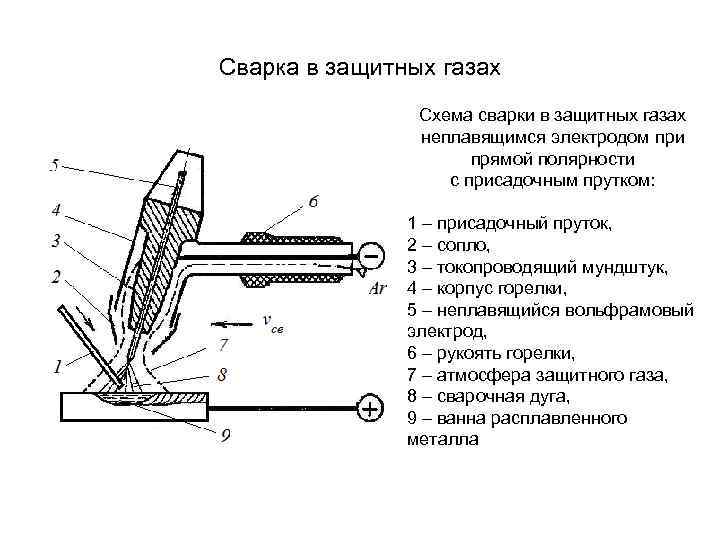
Сварка неплавящимся электродом может использоваться для сваривания разных видов металлов. Она позволяет создать прочные

С помощью электродов АНО-21 проводят сварочные работы при создании стыковых, угловых и нахлесточных соединений.
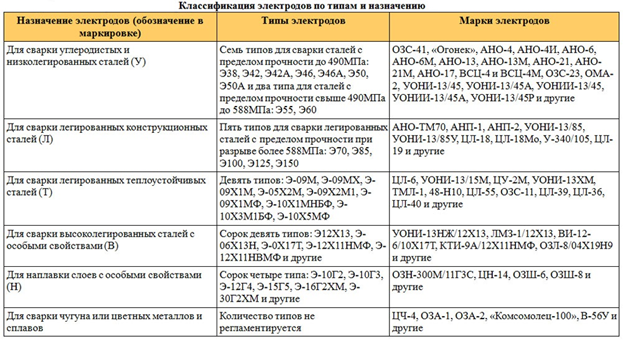
Из этой статьи вы узнаете, какие бывают марки стержней для дуговой ручной сварки, и

Обзорная характеристика электродов от бренда "Монолит" - их основные преимущества и недостатки, свойства и
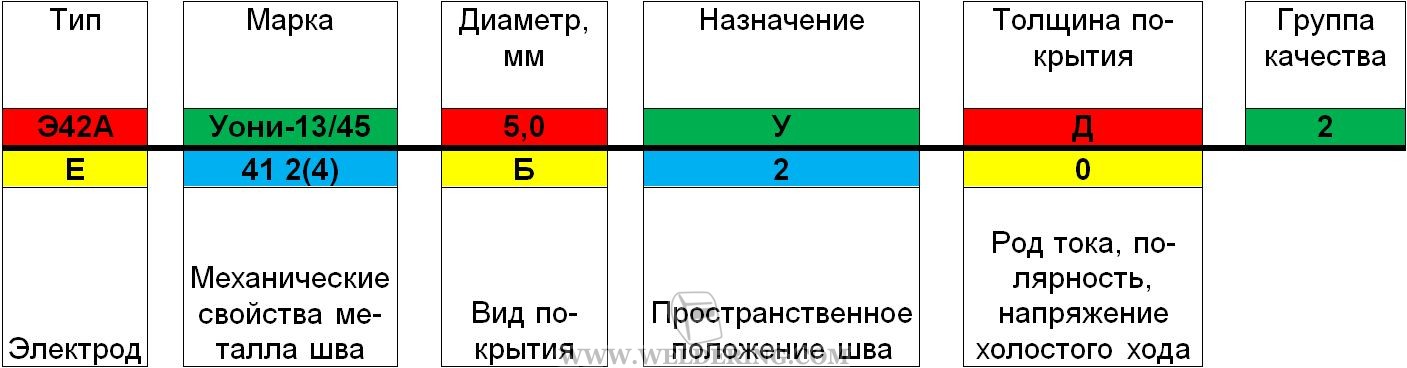
Электроды УОНИ 13 55 — одни из наиболее распространенных и часто используемых расходников при